TLDR;
This deep-dive proposes a cost-efficient framework for identifying hallucinations in abstractive LLM summaries, and uses a combination of AI methods to identify an estimated 82% - 92% of hallucinations.
It includes a proof-of-concept pipeline; a visual example and demo; an evaluation on multiple metrics using a generated test dataset; a cost estimate; and suggested next steps for validation.
Contents
Hallucinations are high-risk in many domains
Many tools use speech-to-text models and large language models to create structured summaries from audio recordings and documents.
Users often make critical decisions based on the summaries that are output. Even small inaccuracies can lead to:
- Mischaracterisation of conversations
- Compromised trust with customers
- Potential legal and ethical issues
More often than not, responsible AI companies are expected by customers to have reliable, deterministic ways to verify the accuracy of AI-generated content.
Defining "hallucinations"
This framework is designed to identify three general forms of hallucinations in the context of AI-generated abstractive summaries:
- Confabulations: The AI creates details that weren’t present in the original conversation.
- Example: Summary says “Client mentioned attending therapy twice weekly” when therapy was never discussed.
- Unsubstantiated claims: The AI makes logical leaps not supported by the conversation.
- Example: Summary says “Client is resistant to medication” based solely on the client mentioning a previous side effect.
- Direct contradictions: The AI states something that directly opposes what was actually said.
- Example: Summary says “Client has stable housing” when they explicitly mentioned being homeless.
Specifically in the domain of frontline work, we see these through the following types of inaccuracies (which have been reflected in the synthetic dataset I've used to test accuracy):
- Factual misrepresentations (demographic details, service history, benefit entitlements, legal status, etc.)
- Temporal inconsistencies (incorrect timelines, wrong duration, future projections)
- Attribution errors (misattributed statements, unspoken actions, false commitments)
- Severity alterations (amplification, minimisation, risk fabrication)
- Cultural/regional misalignments (e.g. non-British terminology)
Introducing Kaleidoscope
Kaleidoscope is designed to detect and flag potential hallucinations in AI-generated summaries.
It incorporates three different methods into a robust fact-checking layer, which ensures that the summaries our users receive are grounded in what was actually said.

In the proof-of-concept pipeline, the first two (deterministic) methods are used to sample candidate hallucinations from summary sentences, before an llm-as-judge evaluator provides a final output.
All three methods, however, can be used as separate hallucination guardrail evals in isolation.
How it works in detail
Semantic Similarity
This compares the meaning of each summary sentence against each transcript sentence, before giving us the summary sentences which aren't similar in meaning to anything in the transcript.
First, we convert each sentence from both the summary and transcript into fixed-size numerical vectors (embeddings) using an S-BERT model, via the Sentence Transformers Python library.
Next, we calculate the cosine similarity between each pair of embeddings, to find the most similar sentence in the transcript for each sentence in the summary.
Finally, we aggregate all the transcript cosine similarity scores for each summary sentence (using either the maximum, mean, or median), to create a single score for each summary sentence.
When a summary sentence has no similar counterpart in the transcript, it signals a potential hallucination.

For the proof-of-concept, I've used all-mpnet-base-v2, which is a pre-trained, 108m parameter model, as it performs well for its size.
We could use a smaller pre-trained model, such as all-MiniLM-L6-v2, which is 5x quicker, or explore fine-tuning an embeddings model ourselves, to improve both quality and speed.
Contradiction
Our second method acts like a logical reasoning test between summary and transcript sentences, checking if one statement contradicts, supports ("entails), or is neutral when compared to another.
We do this using a Natural Language Inference (NLI) model, along with a softmax function to convert the output to probabilities. This means the contradiction, entailment and neutrality scores all add up to 1.
We're particularly interested in contradictions, which indicate potential hallucinations, or entailments (supporting statements), as these indicate factual grounding.

NLI models are a well-established method for detecting factuality or hallucinations in abstractive summaries, with well-known NLP experts such as Eugene Yan, Principal Applied Scientist at Amazon, writing that it's "hard to beat the NLI approach to evaluate and/or detect factual inconsistency in terms of ROI".
For this demo, I've used the pre-trained nli-deberta-v3-base as it performs well on NLI benchmarks, but we could use a lighter-weight pre-trained model, or fine-tune our own with <1,000 samples.
LLM-as-judge
While LLM-as-a-judge evals are simplest to implement, LLMs are (comparatively) slow, expensive, biased to summaries produced by themselves and non-deterministic[1,2,3,4], meaning they can output two different things, when given the exact same input twice.
Therefore, we're using LLM-as-judge methods in conjunction with the two previous deterministic methods, so we get the benefits of both.
Using the below prompt, we use an LLM to identify summary sentences as potential hallucinations, by scoring them between 0 and 1.
Summary Sentence: "{summary_sentence}"
Text to Compare Against: "{compare_text}"
Your task is to determine how likely this summary sentence contains a hallucination when compared to the provided text.
A hallucination is information in the summary that is:
1. Directly contradicted by the text
2. Not supported by any information in the text
3. Making specific factual claims that go beyond reasonable inference from the text
Assign a score from 0.0 to 1.0 where:
- 0.0 means the summary sentence is fully supported by the text
- 0.5 means the summary sentence contains some information not clearly supported but no direct contradictions
- 1.0 means the summary sentence contains clear factual errors or contradictions
Consider:
- Minor paraphrasing or reasonable inferences should score low (closer to 0)
- Completely unrelated content or contradictions should score high (closer to 1)
- Ambiguous cases should be scored in the middle (around 0.5)
Respond with ONLY a decimal number between 0.0 and 1.0, representing your hallucination score.
This is done against the entire transcript, not just a single sentence, so that the LLM has a full view of whether a summary sentence is factually grounded, based on the whole conversation.
Hypothetical example
Below are two summaries from a hypothetical interaction between a social worker and a service user.
The first is summarised in good faith, whereas the second is intentionally a lazy, bad faith summary.
Demo Transcript
Speaker 0: How have you been since we last spoke?
Speaker 1: I've not been great. I've fallen over a few times and felt quite nauseous during the night. I've also had my ex-boyfriend harassing me on the phone, which has made me nervous for my safety. It's not much different to the last time we spoke.
Speaker 0: Have you spoken to the GP about your nausea and falls?
Speaker 1: I've tried to book an appointment, but it requires me to wake up at 8AM which is much earlier than I am able to, as I get awful sleep due to the nausea at the moment.
Speaker 0: OK, I'll book in a GP appointment for you after this session.
Summary Comparison
Summary 1
The social worker initiated the meeting by asking the service user about their recent well-being.
The service user reported ongoing difficulties, including multiple falls, persistent nausea at night, and safety concerns due to repeated phone harassment from their ex-boyfriend.
The service user expressed feeling nervous and indicated that these issues are similar to those discussed previously.
The social worker enquired if the service user had spoken to their GP regarding the falls and nausea.
The service user explained their difficulty in scheduling an appointment due to poor sleep caused by their nausea, as they find it challenging to wake up early enough to book an appointment.
In response, the social worker acknowledged the issue and offered to arrange a GP appointment on the service user's behalf after the session, aiming to address their physical health concerns.
Action Items:
Social worker to schedule a GP appointment for the service user immediately after the session.
Summary 2
The service user mentioned that things have been relatively stable and that there hasn't been much change since the last meeting.
They seem to be in a similar position as before, with no significant new issues to discuss.
Action Items:
Social worker to buy the service user a new phone.
Social worker to send the service user a birthday card.
Visualisation of sentence comparisons
The graph below shows comparisons between each sentence in either summary, against each fragment in the transcript.
Using an example threshold set for the NLI model and semantic similarity, you can see the colour-coded likelihood of a sentence being a hallucination.
[Click + drag to change angle, scroll to zoom, hover over points for details]
Testing Kaleidoscope's accuracy
In order to test the effectiveness of each individual method as well as the combination (or weighted ensemble) of methods, we need a dataset with ground-truth labelled hallucinations.
Generating a test dataset as a benchmark
I've used o3-mini (due to its larger 100k output context window), along with structured outputs, to create a synthetic dataset of 100 transcripts, along with 100 corresponding summaries in a strict JSON schema, each with 15-20 sentences, of which 1-3 are hallucinations.
[You can see the Colab notebook used to generate the synthetic transcript and summary pairs here.]
This gives us 963 summary sentences (of which 204 are hallucinations), which I'll use to test the models and methods against.
Choosing our metrics
We now have a dataset with classifications of whether a given generated summary sentence is a hallucination or not, which we can use to test our models.

There's a number of metrics we can use to test effectiveness in classification problems, for example:
- Accuracy: How often the model is correct in identifying both hallucinations and non-hallucinations, as a proportion of total.
- Precision: Of the sentences identified by the model as hallucinations, what proportion were actually hallucinations.
- Recall: Of all the actual hallucinations, what proportion did the model correctly identify.
- F1 Score: The harmonic mean of precision and recall, which provides a balanced score between the two.
- F2 Score: Similar to F1 score but gives more weight to recall, which is useful here as we care more about recall than precision.
Of the above recall and F2 Score are the ones that we care about more, as we're more willing to have a larger proportion of false positives (incorrectly flagged non-hallucinations) than false negatives (actual hallucinations that went unnoticed).
We also care about accuracy, as it's an important top-level metric about how the model performs.
The Results
Individually, I tested each method on the generated test dataset, using different methods of aggregation across transcript sentences (e.g. max, mean, sum), and different thresholds.
These are the best results per each method, sorted by F2 score:
| Metric | Threshold | Accuracy | F1 score | F2 score | ROC AUC |
|---|---|---|---|---|---|
| llm_judge_hallucination_score | 0.51 | 0.92 | 0.78 | 0.72 | 0.84 |
| cosine_similarity_max | 0.49 | 0.82 | 0.64 | 0.71 | 0.85 |
| cosine_similarity_mean | 0.29 | 0.68 | 0.51 | 0.65 | 0.80 |
| cosine_similarity_median | 0.30 | 0.56 | 0.45 | 0.63 | 0.77 |
| nli_contradiction_sum | 0.01 | 0.35 | 0.38 | 0.59 | 0.68 |
| nli_contradiction_max | 0.01 | 0.40 | 0.38 | 0.57 | 0.64 |
| nli_contradiction_mean | 0.00 | 0.21 | 0.35 | 0.57 | 0.68 |
| nli_entailment_mean | 1.00 | 0.21 | 0.35 | 0.57 | 0.61 |
| nli_entailment_max | 1.00 | 0.21 | 0.35 | 0.57 | 0.66 |
| contradiction_over_50 | 0.00 | 0.21 | 0.35 | 0.57 | 0.66 |
| contradiction_over_70 | 0.00 | 0.21 | 0.35 | 0.57 | 0.66 |
| contradiction_over_90 | 0.00 | 0.21 | 0.35 | 0.57 | 0.65 |
| entailment_contradiction_ratio | 1.00 | 0.76 | 0.29 | 0.26 | 0.67 |
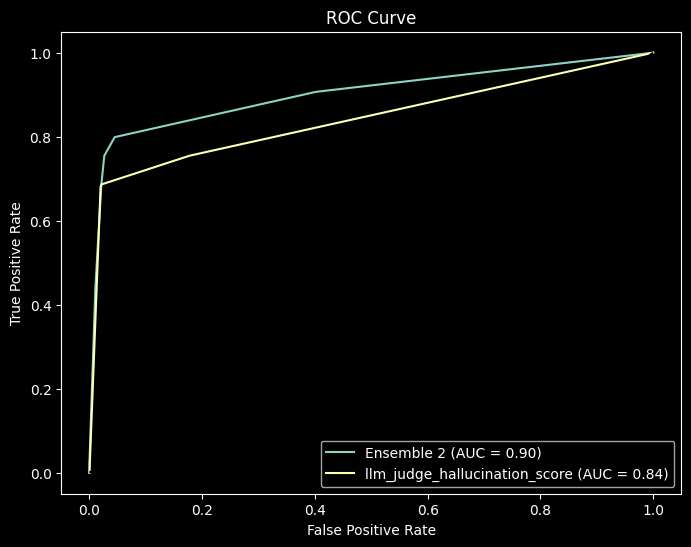
Below is the ROC curve for the weighted ensemble of the three methods, using logistic regression, vs. the best performing individual method:
Here's what their respective confusion matrices look like:
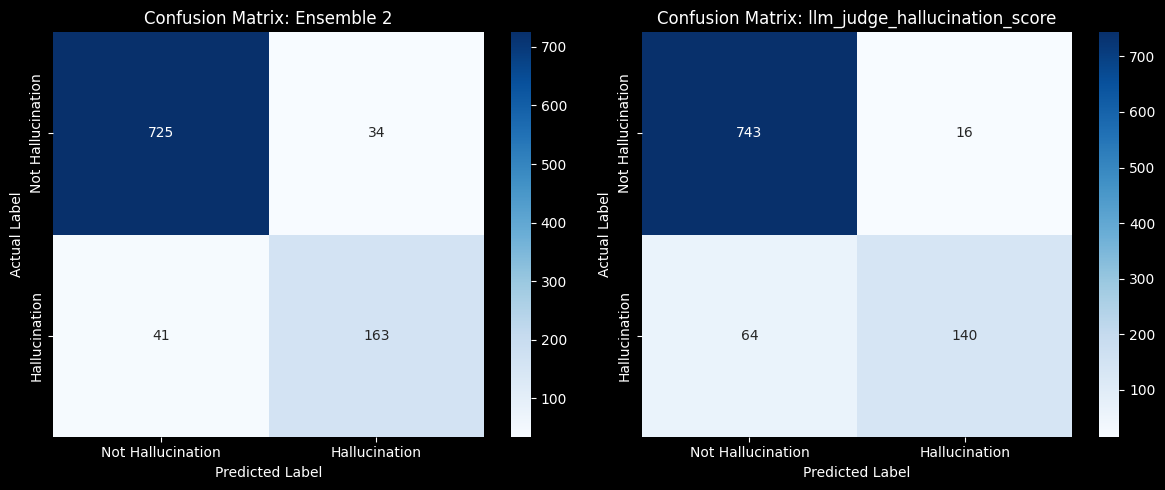
Ultimately, the ensemble of three methods performed better than any individual method, with an accuracy of 92.2%, recall of 0.799 and an F2 Score of 0.804 on the test dataset.
This is with zero optimisation for quality, speed, or cost, using pre-trained off-the-shelf NLI and embeddings models, so likely represents the lower-bound of what is achievable.
Estimated cost
Implementing this would roughly cost ~£100-125 in AWS EC2 and OpenAI API fees, with a naive implementation per 1,000 summaries.
This assumes:
- An average transcript length of 20 minutes
- Average summary length of 20 sentences
- Using AWS EC2 to run the embeddings and NLI models, via Huggingface
- ~0.25-0.5 hours on a GPU instance for the embeddings (bi-encoder) model, to provide embeddings for ~195k sentences
- ~50-100 hours on a GPU instance for the NLI (cross-encoder) model, as you'd need to run NLI on every summary sentence against every transcript sentence, which is ~3.5m sentence pairs
- ~2m tokens on GPT-4o or similar model for llm-as-judge
Cost could be hugely optimised using selective processing or sampling for the NLI model (e.g. only calculating it for a given summary based on user invoking the process), or by using a lightweight model for LLM-as-judge evaluators.
If optimised, it could easily cost less than £20 per 1,000 summaries.
Next Steps
- Get feedback
- Improve the benchmark hallucination data to be more representative and life-like
- Test different pre-trained models, to see what the trade-off in speed, cost and quality is
- Fine-tune embeddings and NLI models, to see impact on metrics and performance